

Business
All About 1.3m August Novemberlapowskyprotocol
1.3m August Novemberlapowskyprotocol: If you’ve read anything about Facebook in the last few months, it would be hard to miss the mention of experiments that sought to manipulate users’ emotions. Though details were scarce, speculation ran rampant and people were outraged. Now, finally, we have some answers.
Internal documents from Facebook reveal that the company – which owes its share of privacy scandals – withheld certain protections from a subset of users to see how they would react without them.
The release of the documents is the consequence of a series of disclosures from Facebook regarding how it conducted experiments on unsuspecting users. The experiments were done to learn more about how users respond to changes in the News Feed, and whether their responses were different depending on their location, gender, or relationship status.
For example, Facebook has experimented with showing some users stories about people using Facebook in unusual places – such as friends who were abroad at the time – to see whether that would make them more likely to use it themselves.
The documents also show that Facebook tested different versions of the News Feed that included stories about different events, such as videos of fires and shark attacks.
A separate experiment sought to see whether telling users that their friends had seen the posts they had written decreased their engagement. The experiment tested two separate messages: one saying that 25 percent of the friends they were writing to had already seen the post, while a second said everyone saw it.
Facebook also conducted an experiment to determine if showing more posts from media companies would increase the time Facebook users spent on the News Feed by 10 minutes.
In each case, Facebook found that there was no change in user behavior.
The documents show that Facebook revealed some of these experiments in response to a series of inquiries from regulatory agencies and Congress about whether the company had violated people’s privacy by conducting experiments on them and altering their News Feed for commercial gain.
However, the documents show that Facebook never considered telling users about the experiments.
The New York Times has released these documents in response to a subpoena from Senator Mark Warner, who chairs the Senate’s Permanent Subcommittee on Intelligence. Warner said he wanted to know whether Facebook had violated terms of service or its own privacy policies.
Facebook said it was legally obligated not to reveal any information about user reactions data and that only the company had direct access to that data.
“We carefully consider what we disclose to third parties – and in some cases, we give them additional info about how we use their info,” Facebook wrote. “But because the information is tightly guarded, we can’t share all the details.”
Facebook also said it had never talked to any government agency about any of its data collection efforts. The company said it had only disclosed information in response to formal requests from federal agencies, including Congress.
Experts suggest that Facebook, like Google and other tech companies, does not consider the user an individual whose rights need to be protected. They treat the user as a product for sale, an asset which can be experimented on.
The experiments are particularly disturbing because they seem to have been conducted purely out of curiosity – one wonders what exactly they were trying to find out by withholding privacy protections – and at the expense of users’ security and well-being.
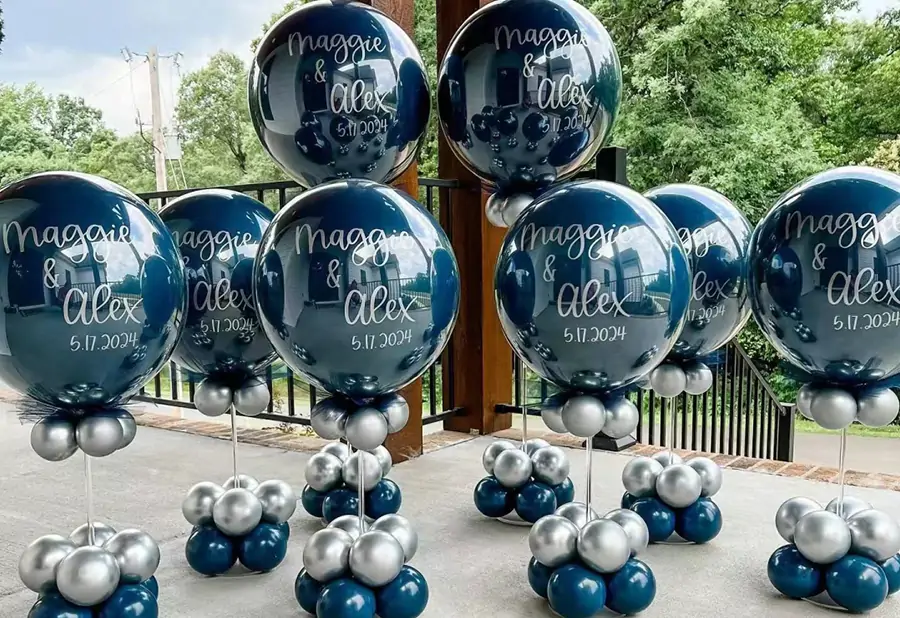
There’s always plenty to see at events, all carrying different messages, brands, and graphics. Businesses seek effective yet cost-efficient methods of getting noticed at neighborhood fairs, trade events, product launches, and shop openings – custom printed balloons offer one such simple yet effective means – when utilized wisely, they help companies get noticed more effectively, create lasting memories more naturally, while strengthening their identity without seeming forced or faked out.
Visual Impact For Quick Visual Results
First impressions matter at events where attendees must quickly make choices about where and who to visit, such as launches of personalized balloons at events. Balloons printed with your design add height, color, and movement right away, while being easy to see in dense environments due to being larger and catching people’s eyes from all directions in a room.
Companies can turn balloon decorations into promotional tools by printing logos, slogans, or campaign messaging directly on balloons. These graphics draw people’s attention naturally, whether hung over a booth or framing an entrance – without needing to be actively promoted!
How Brand Identity Is Shaped Through Design
Brand consistency is at the center of successful branding efforts, so companies may use custom balloons to integrate their brand identity into an event environment through familiar colors, typefaces, and messages that people recognize from previous experiences with them. When used alongside banners, table coverings, or brochures for increased professionalism.
Consistency in visuals helps people recall your brand. Repeated exposure of logo or message throughout an event – even for just short time frames – has the ability to leave lasting memories with participants that build relationships between attendees. Over time, these reminders help strengthen mutual understanding among attendees.
Promote Interaction And Engagement
Not being noticed at events alone isn’t enough; engagement must also happen between attendees. Balloons inherently make people engage, particularly at locations that stimulate mobility and exploration; many visitors often stop for photos, questions, or free balloons at these events.
Businesses often utilize custom printed balloons at events to encourage participation from attendees and expand the brand message beyond the event, reaching people both physically and on social media, by giving attendees balloons as souvenirs of an experience or product demonstrations. When attendees take balloons home with them from these activities and carry the brand message out into the region and beyond social media, more people receive information from this brand message about its existence than would normally come through at just a one-day conference event itself.
Help With Affordable Event Marketing
Balloons can be an inexpensive and impactful way to promote any message or event, especially since their cost per impact can be so minimal. Balloons are easy to produce in large volumes at little expense; transportable; quick to set up; making them appealing solutions for firms attending many events with limited marketing resources or attending many similar occasions.
Balloons can make any room pop with color. By taking advantage of the balloon’s eye-catching nature, even small quantities may drastically transform its aesthetics, enabling businesses to spend their budget more wisely while creating an eye-catching presence that still gets people talking and involved.
Acclimatizing To Various Events And Situations
One of the greatest things about custom printed balloons is their versatility – they work for many events and businesses alike! Companies use balloons at conferences, networking events, grand openings, and sales events; stores use them during grand openings; nonprofit organizations can utilize balloons as fundraising devices, while community groups make use of balloons to raise money and spread awareness for their cause.
Make the balloon designs reflect the occasion: bright colors and eye-catching messages might work well at festivals and family reunions; more muted hues with less branding can work for professional settings or meetings. By accommodating to different events’ moods and settings, balloons remain interesting to a wide range of people.
Use Balloons In Your Plan
Balloons work great when integrated into an overall event marketing plan, which should include clear messages, courteous personnel interactions, and strong calls-to-action. Businesses that excel are those that carefully consider where things will be put while matching designs to the goals of an event.
Businesses often enlist skilled promotional partners such as Perfect Imprints to ensure that the balloon designs meet brand guidelines and event goals, thus turning a simple item into an effective marketing tool.
Final Thoughts
To stand out in competitive event venues, companies need to use visual elements creatively and with purposeful intent. Custom-printed balloons offer companies an effective means of drawing attention without overcomplicating their approach – when used strategically, they provide unforgettable memories and will stay with people long after an event has concluded.

Construction disputes are generally tense and complex for homeowners builders contractors. Your awareness of your rights in the event of a dispute is essential to effective settlement of the dispute. Delays substandard work contract breaches or payment problems are all possible elements of such disputes. Confidence to deal effectively with the problems can be gained through acquaintance with the legal construct of construction contracts. Misunderstanding or vague words of a contract usually cause disputes that can bring in confusion to the two parties. Protection of your interests entails your knowledge of your own legal responsibilities and rights as a builder or a homeowner.
When Should You Hire a Building Disputes Solicitor?
Seeking legal advice at an early stage is important in the case of a construction dispute. If a dispute with a contractor or homeowner gets out of hand beyond simple miscommunication legal guidance may be necessary. Your rights will be protected and your case will be dealt with properly if you instruct a solicitor. A building disputes solicitor can provide you with the tools you require to proceed with your dispute by clearly establishing your rights and responsibilities under the contract. They can help you decide if the most appropriate action is arbitration mediation or litigation. By helping to resolve the conflict amicably their intervention may sometimes prevent it from escalating.
How Solicitors Help Resolve Disputes Over Variations and Change Orders
Change orders and variation clauses are standard in construction contracts and they sometimes result in conflict. Because of unforeseen occurrences or changing requirements during the project these clauses authorize changes to the original scope of work. However there could be conflicts regarding the scope of the changes or associated costs. A building disputes solicitor can prove to be extremely useful in such circumstances with regards to understanding the conditions of the contract. They will help establish if the prescribed procedures for authorizing variations have been complied with and if the variation orders are within the contract terms. In a bid to reflect changes precisely solicitors also help in preparing addenda or contract amendments. For additional work they can verify the billing to ensure that it is fair and according to the contract.
By obtaining legal counsel both sides can avoid misunderstandings and miscommunications that may lead to long and costly court cases. In some instances lawyers may suggest mediation or negotiation as other dispute resolution methods which can lead to faster and more cost-effective settlements. If a settlement is not possible in more serious cases the attorney can prepare for litigation and represent your interests in court.
Dealing with Owner-Builder Disputes: What Legal Protections Apply?
While dealing with owner-builder disputes is sometimes challenging it is very important to know your legal rights. Owner-builders are obligated by law in most jurisdictions to comply with specific insurance and licensing regulations which act to protect both parties in future disputes. If issues arise such as construction defects delays or payment disputes the owner or contractor can seek recourse under consumer protection or contract law. Owner-builders generally must provide guarantees in relation to the materials and workmanship for a set period as per the law. It is often recommended that mediation or arbitration be considered prior to going to court if the dispute cannot be resolved through friendly settlement. By getting the services of a lawyer at the earliest you can make sure that you comply with correct procedures and avoid costly mistakes by having your rights and duties explained. With the correct documents like signed agreements variation orders and letters you can increase the chances of a lawsuit victory. Owner-builder disputes can be resolved ultimately faster fairly and with less hassle if you know your rights and have professional guidance.

In the fast-paced realm of entrepreneurship, small businesses face both thrilling opportunities and formidable challenges on the path to growth. The journey from fledgling startup to thriving enterprise is fraught with pivotal decisions that can spell success or failure. With market dynamics in perpetual motion, how does one ensure a business not only survives but thrives? The secret lies in unlocking the right strategies that cater to scalability, financial robustness, and market adaptability. This article delves into the essential considerations small business owners must keep in mind to steer their ventures toward sustained growth and success.
Growing Pains or Gains Ensuring Scalability Without Compromising Quality
As a small business owner, envisioning growth is exciting, but it also comes with its own set of challenges. One critical aspect to address is scalability. Can your business model expand without sacrificing quality or customer satisfaction? By focusing on scalability, you can streamline operations and optimize processes, achieving economies of scale that lower costs per unit as your business grows. This means enjoying higher profit margins without compromising the value delivered to your customers. Efficient resource allocation is key, ensuring that time, money, and manpower are directed towards essential tasks. This flexibility allows your business to remain responsive to market changes, setting the stage for long-term success.
Financial Foundations Crafting a Blueprint for Business Growth
Funding your growth initiatives requires a solid financial strategy. It’s crucial to develop a comprehensive financial plan that includes effective budgeting, meticulous cash flow management, and exploring diverse funding sources. By setting clear financial goals aligned with your strategic aims, such as market expansion or operational efficiency, you can ensure your budget is actionable. Implementing a robust cash flow monitoring system is vital to maintain liquidity and avoid financial shortfalls. Additionally, diversify your funding portfolio by exploring options like crowdfunding or angel investors. This multidimensional approach not only supports immediate growth opportunities but also builds resilience against financial uncertainties.
Brand Brilliance Enhancing Your Presence Through Strategic Marketing
To capture a wider audience, enhancing your brand identity and marketing strategy is essential. As we move into 2025, integrating trends like artificial intelligence, short-form videos, and sustainable practices will redefine consumer engagement. Strengthening your brand involves creating a memorable experience that resonates with your target market. A data-driven approach allows you to personalize marketing efforts, increasing engagement and brand loyalty. By continuously refining your communication techniques and leveraging social proof, you can effectively highlight the unique benefits of your offerings and stand out in a competitive market.
Digital Dreams Realized Transforming Your Business for Growth
In today’s fast-paced market, digital transformation is crucial for small businesses aiming to streamline operations and boost competitiveness. Embracing technologies such as cloud computing and advanced AI can scale your operations and enhance customer experiences by personalizing engagement and improving efficiency. Digital initiatives can significantly uplift customer satisfaction and loyalty, driving higher revenue and market share. Integrating digital strategies isn’t just an option for survival; it’s a pathway to thriving in an increasingly competitive landscape.
Building a Dream Team Enhancing Talent Retention Through Culture
Cultivating an organizational culture that attracts and retains top talent is essential for business growth. This involves fostering effective team dynamics where open communication, learning opportunities, and diversity are prioritized. A competitive workplace environment is crucial, as many employers struggle with employee retention and attracting new talent. By establishing an appealing employee value proposition, you can significantly reduce turnover costs. Creating a supportive and inclusive atmosphere not only enhances employee satisfaction but also drives long-term business success.
Insight-Driven Triumphs Harnessing Market Insights for Strategic Growth
Thriving in a competitive marketplace requires thorough market research and competitive analysis. Understanding emerging trends allows you to identify new opportunities and potential threats that impact your business growth. Evaluating competitors’ offerings and customer feedback provides a clear comparative landscape. Regularly assessing your strengths and weaknesses using SWOT analysis ensures adaptability to market changes. These insights inform strategic decisions, helping you create innovative strategies that propel your business forward.
Efficient Invoicing for Seamless Expansion
A consistent and simple invoicing system is essential for expanding your small business efficiently. By using an online invoice builder, you can generate professional invoices that reflect your brand identity, including your logo and company colors. Setting precise payment terms and issuing invoices promptly enhances your cash flow management, ensuring timely payments. Offering various payment options caters to diverse customer preferences, reducing barriers to payment and fostering stronger client relationships. Embracing customizable invoice templates allows you to save time and effort, ultimately freeing up resources to focus on strategic growth initiatives.
The road to small business growth is far from linear; it’s a dynamic journey filled with evolving challenges and opportunities. As you navigate this ever-changing landscape, remember that success hinges on adaptability, resilience, and strategic foresight. By embracing scalable operations, crafting robust financial plans, and leveraging modern marketing and digital tools, you align your business with the demands of tomorrow’s market. Moreover, fostering an organizational culture that prioritizes talent retention and capitalizing on market insights can propel your venture forward. The canvas of small business is vast, painted with the vibrant hues of innovation and perseverance. Let these considerations guide your brush strokes as you create a masterpiece of sustainable growth and enduring success.

 Business5 years ago
Business5 years agoFind out how useful a loan is without a credit check
- Digital Marketing5 years ago
Is YouTube Marketing Capable of Taking Your Business to the Next Level?
- Food5 years ago
5 Best and Worst Foods for Boosting Metabolism
- Business5 years ago
Content Creation Tips Every Digital Manager Needs to Know
- Business4 years ago
Best Workplace Upgrade
- Lifestyle5 years ago
How to Choose the Best Air Fryer for Me
 Fashion5 years ago
Fashion5 years ago8 Top Leather Jacket Picks To Try Out This Year
- Tech5 years ago
Food Lion Employee Login at ws4.delhaize.com – MyHR4U















